If you’re leading operations or technology at a 3PL or asset pooling company, your role should be focused on improving fleet utilization, tightening asset cycles, and getting more value from your tracking investments.
You should certainly not be spending hours every week reconciling mismatched location logs, filling in data gaps, or manually cross-referencing reports from disconnected systems.
But that’s exactly where most teams end up.
The industry has made significant progress in deploying trackers on reusable assets like plastic pallets, roll cages, and specialized carriers.
The hardware is better, coverage is wider, and there’s no shortage of data being generated. The problem is what happens to that data after it’s collected.
Noisy tracking data – incomplete pings, duplicate entries, unindexed records from multiple sources, gaps during transit, and information that never makes it into your ERP or WMS – doesn’t just sit harmlessly in the background.
It actively distorts how your team sees and manages asset flow.
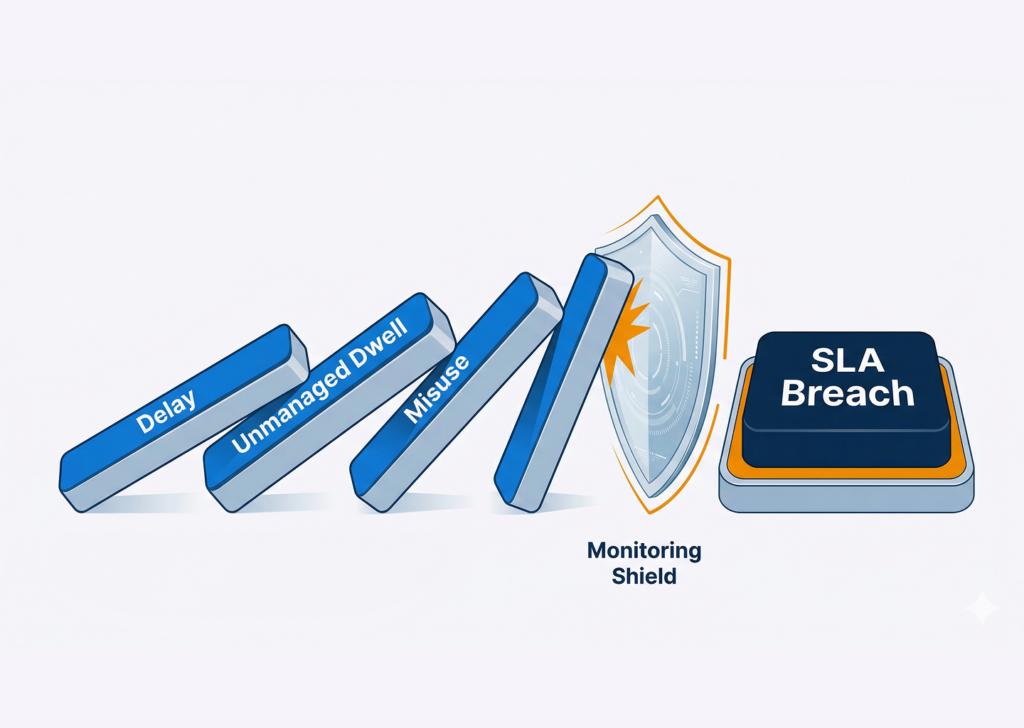
It leads to wrong decisions made with a false sense of confidence, delayed recoveries, phantom inventory counts, and a constant low-grade operational drag that keeps going on without any possible solution or permanent resolution.
But this is what makes it particularly damaging for returnable assets operations: unlike one-way shipments, RLCs move in loops. Every data error gets compounded over multiple cycles.
A single misreported location or a missed scan at one node doesn’t just affect that trip – it cascades into inaccurate utilization metrics, flawed demand forecasts, and misallocated capital across your entire fleet.
It is therefore, important to address the issues with data management in returnable assets operations and the solutions.
This blog breaks down how noisy data erodes the returns on your tracking investment and why optimizing the data layer is the single highest-leverage move that most operations teams often ignore.
What makes tracking data “noisy” in returnable assets operations?
Most logistics teams are drowning in data. The issue is that very little of it is clean enough to act on.
When you’re tracking thousands of reusable pallets, roll cages, and specialized carriers across multiple locations, handlers, and transit legs, data comes in from everywhere.
GPS pings from trackers, scan logs from warehouse floors, manual entries from drivers, event data from WMS and ERP systems. Each source generating its own stream, in its own format, at its own frequency.
The problem starts when none of this is indexed or reconciled at the point of collection.
What does noisy tracking data actually look like in practice?
It looks like location pings that arrive out of sequence or with gaps during transit, making it impossible to trace a reliable route for a single pallet.
It looks like duplicate entries created when the same asset gets scanned by two different systems at the same facility.
It looks like temperature or shock readings that exist in one platform but never make it into the WMS where the compliance team actually needs them.
It also looks like data that is technically “complete” but operationally useless, because without integration across systems, a location update in your tracking dashboard and an inventory count in your ERP are two separate versions of reality.
When those don’t match, someone on your team has to manually figure out which one is right.
How does the operational cost show up?
Noisy data isn’t really obvious before it starts to create issues.
It leads to recovery teams being dispatched to wrong locations, fleet counts that don’t reflect what’s actually in circulation, replacement orders placed for assets that aren’t actually lost, and SLA reports built on numbers that no one fully trusts.
For operations and technology leaders, the frustration isn’t the errors alone. It’s the time spent finding and fixing them instead of improving utilization and tightening asset cycles.
Your team ends up spending its best hours compensating for data problems that shouldn’t exist in the first place. That time has a cost, and it compounds every single week.
Why manual fixes and conventional solutions don’t scale
The first instinct most teams have when data gets messy is to fix it manually. Someone pulls a report, spots the gaps, cross-references it against another system, and corrects the entries. It works when you’re managing a few hundred assets across two or three locations.
It stops working after a point.
As your fleet of reusable pallets or roll cages grows into the thousands, and the number of handlers, facilities, and transit legs multiplies with it, manual reconciliation becomes a recurring time sink.
Your operations team ends up building spreadsheets on top of spreadsheets, creating their own workaround logic to make sense of data that should have been clean from the start.
And conventional tracking platforms don’t solve this either.
Most of them were built to answer one question: where is the asset right now? They collect location pings and maybe a few sensor readings, dump them into a dashboard, and leave everything else to you.
The reconciliation, the deduplication, the cross-referencing with your WMS or ERP, the interpretation of what a particular pattern of data actually means for your operations, all of that still falls on your team.
What about the compounding problem specific to returnable assets?
One-way shipments have a start and an end. If there’s a data error, it affects that single trip and you move on.
Returnable assets don’t work that way. A plastic pallet or a roll cage might cycle through five or six nodes in a single loop, and then repeat that loop dozens of times a year.
A missed scan at one node, a misreported location at another, or a gap during one transit leg doesn’t just create a one-time inaccuracy.
It feeds wrong data into utilization calculations, fleet planning models, and recovery scheduling across every subsequent cycle.
Over six months of operations, a 3PL managing tens of thousands of returnable assets can accumulate enough compounding data errors that their reported fleet availability and their actual fleet availability are two very different numbers.
At that point, the team isn’t managing assets anymore. They’re managing the gap between what the system says and what’s actually happening on the ground.
That gap is where capital gets wasted, recoveries get delayed, and replacement budgets keep inflating without a clear explanation.
How observability and intelligent data engines solve this at the source?
The conventional approach to tracking data treats every ping, scan, and sensor reading as an isolated event.
Something happened, here’s a record of it. What that event means in the context of a larger asset journey, whether it’s accurate, whether it conflicts with another data point from a different source, that interpretation is left entirely to your team.
But, observability works differently. It’s a concept borrowed from software engineering, where systems are built to continuously monitor themselves, detect anomalies, and surface only what matters based on context.
When you apply that same logic to physical assets like reusable pallets, roll cages, and specialized carriers, the data layer starts doing the heavy lifting that operations teams have been doing manually.
What does that look like for returnable assets operations?
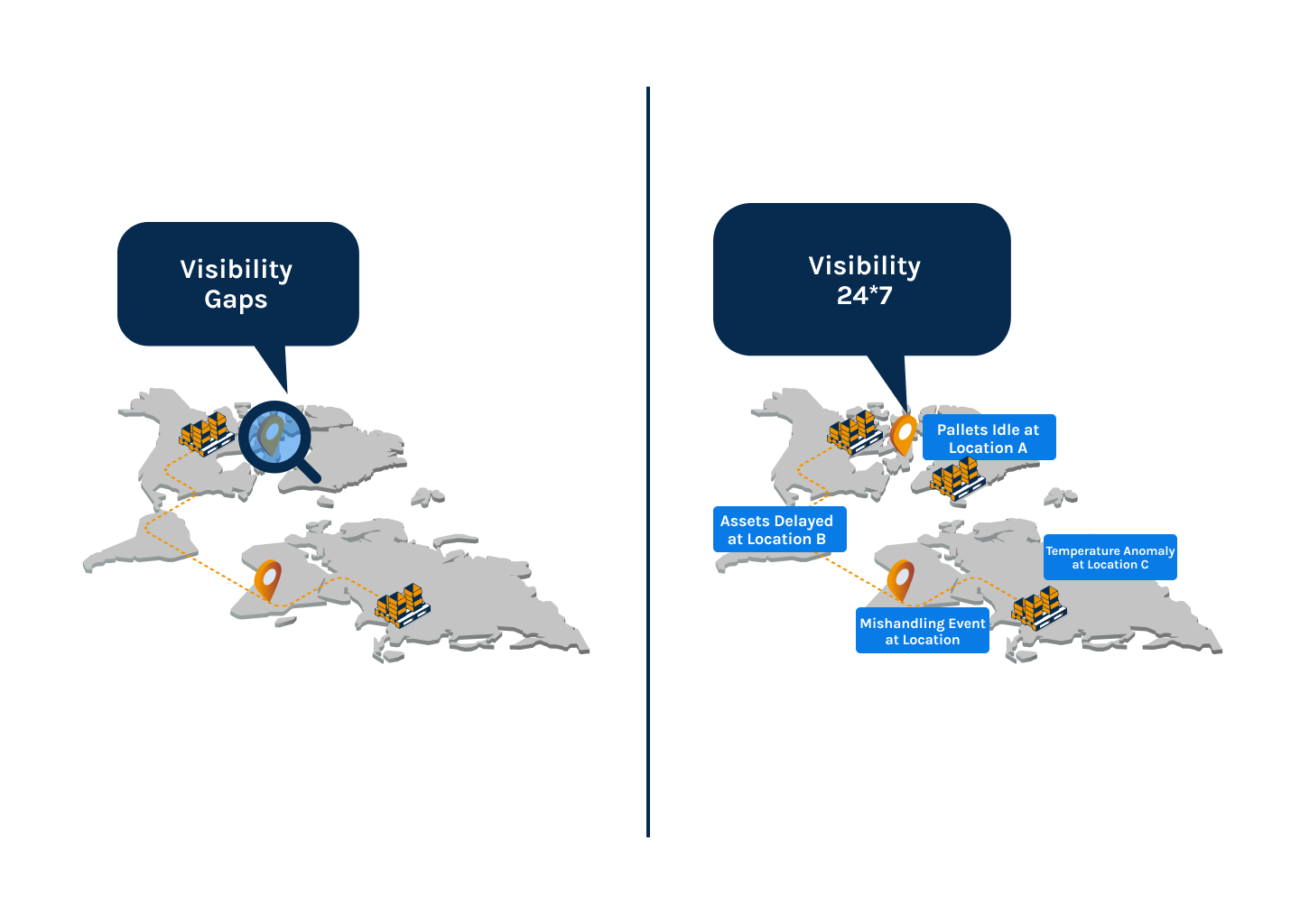
Instead of raw GPS pings landing in a dashboard for someone to interpret, an observability-driven platform ingests data from every source, indexes it against the asset’s known journey, deduplicates it, fills context gaps using pattern recognition, and flags only the anomalies that require attention.
A location ping that seems off gets validated against route history and neighboring sensor data before it ever becomes a line item in a report.
This is what Acceleronix, the data engine that powers SensaTrak, was built to do.
Acceleronix processes and contextualizes tracking data at the point of ingestion, before it reaches your dashboard, your ERP, or your WMS. It handles the indexation, reconciliation, and cross-referencing that would otherwise sit on your operations team’s plate.
When data flows into your existing systems through SensaTrak’s integrations, it arrives clean, structured, and matched to the right asset lifecycle stage.
What changes for your operations team when this works?
Fleet counts in your ERP reflect what’s in circulation.
Recovery scheduling is based on validated location data, not best guesses.
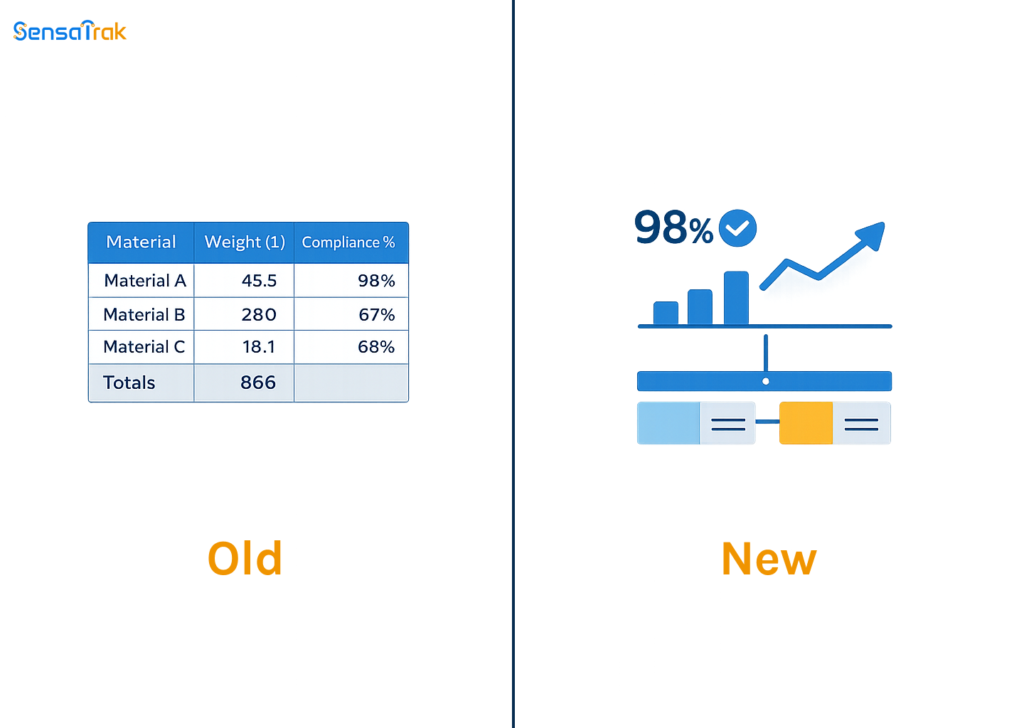
Compliance reports pull from a single reconciled data source instead of loosely plugged exports from four different platforms.
And your operations and technology leaders get to spend their time on utilization improvements and cycle optimization instead of chasing data discrepancies.
The data layer stops being something your team has to manage around. Now, it just does, what it should have been doing all along.
Data quality should be built into your operations infrastructure
Most organizations treat data cleanup as a recurring task, something the ops team or the IT team handles alongside everything else.
A few hours here reconciling spreadsheets, a few hours there chasing mismatches between systems. It’s accepted as part of how asset tracking works.
It shouldn’t be.
When your tracking infrastructure generates clean, indexed, and contextualized data from the point of collection, the entire operating rhythm changes. Decisions move faster because the numbers are trustworthy.
Your teams can now make decisions faster, because you get figures that are trustworthy.
Your fleet planning gets more accurate because utilization data is closer to the reality.
And finally, your compliance reports now just take minutes instead of half a day of verifying files together.
For operations heads and technology leaders at 3PLs and asset pooling companies managing large fleets of returnable assets, this is the most efficient use of your time and resources.
Better data quality at the source means fewer people spending time on reconciliation, fewer capital decisions based on flawed numbers, and fewer recovery cycles wasted on outdated information.
Platforms built on observability principles, powered by engines like Acceleronix, make this the default rather than something your team has to build workarounds for.
SensaTrak was designed around this idea: that logistics teams should be running operations, and the data layer should take care of itself.
Want to know if we can achieve this for you too?